Log analytics
Data Prepper is an extendable, configurable, and scalable solution for log ingestion into OpenSearch and Amazon OpenSearch Service. Data Prepper supports receiving logs from Fluent Bit through the HTTP Source and processing those logs with a Grok Processor before ingesting them into OpenSearch through the OpenSearch sink.
The following image shows all of the components used for log analytics with Fluent Bit, Data Prepper, and OpenSearch.
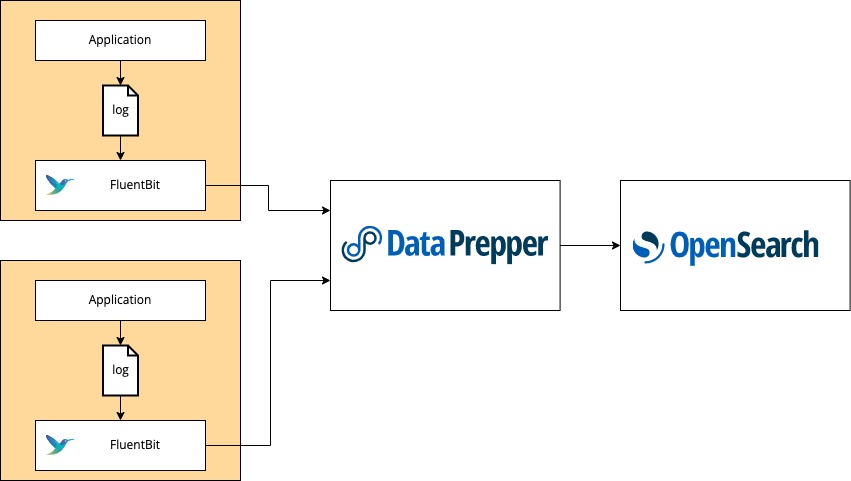
In the application environment, run Fluent Bit. Fluent Bit can be containerized through Kubernetes, Docker, or Amazon Elastic Container Service (Amazon ECS). You can also run Fluent Bit as an agent on Amazon Elastic Compute Cloud (Amazon EC2). Configure the Fluent Bit http output plugin to export log data to Data Prepper. Then deploy Data Prepper as an intermediate component and configure it to send the enriched log data to your OpenSearch cluster. From there, use OpenSearch Dashboards to perform more intensive visualization and analysis.
Log analytics pipeline
Log analytics pipelines in Data Prepper are extremely customizable. The following image shows a simple pipeline.
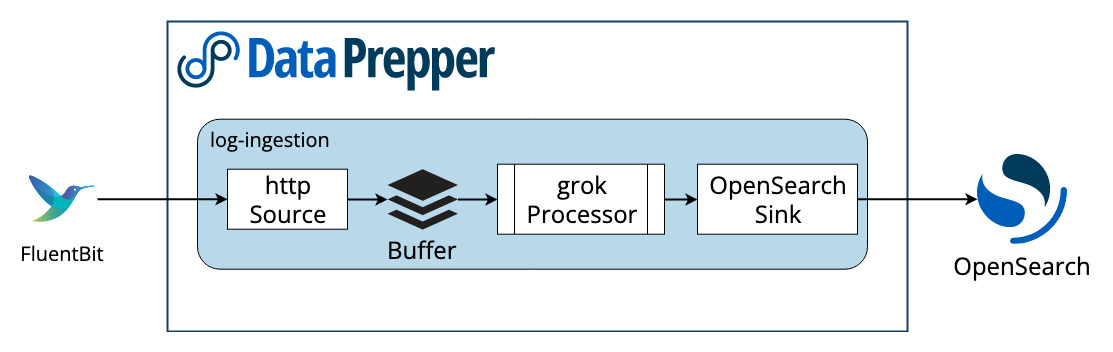
HTTP source
The HTTP Source accepts log data from Fluent Bit. This source accepts log data in a JSON array format and supports industry-standard encryption in the form of TLS/HTTPS and HTTP basic authentication.
Processor
Data Prepper 1.2 and above come with a Grok Processor. The Grok Processor is an invaluable tool for structuring and extracting important fields from your logs, making them more queryable.
The Grok Processor comes with a wide variety of default patterns that match common log formats like Apache logs or syslogs, but it can easily accept any custom patterns that cater to your specific log format.
For more information about Grok features, see the documentation.
Sink
There is a generic sink that writes data to OpenSearch as the destination. The OpenSearch sink has configuration options related to an OpenSearch cluster, like endpoint, SSL/username, index name, index template, and index state management.
Pipeline configuration
The following sections discuss pipeline configuration.
Example pipeline with SSL and basic authentication enabled
This example pipeline configuration comes with SSL and basic authentication enabled for the http-source:
log-pipeline:
source:
http:
ssl_certificate_file: "/full/path/to/certfile.crt"
ssl_key_file: "/full/path/to/keyfile.key"
authentication:
http_basic:
username: "myuser"
password: "mys3cret"
processor:
- grok:
match:
# This will match logs with a "log" key against the COMMONAPACHELOG pattern (ex: { "log": "actual apache log..." } )
# You should change this to match what your logs look like. See the grok documenation to get started.
log: [ "%{COMMONAPACHELOG}" ]
sink:
- opensearch:
hosts: [ "https://localhost:9200" ]
# Change to your credentials
username: "admin"
password: "admin"
# Add a certificate file if you are accessing an OpenSearch cluster with a self-signed certificate
#cert: /path/to/cert
# If you are connecting to an Amazon OpenSearch Service domain without
# Fine-Grained Access Control, enable these settings. Comment out the
# username and password above.
#aws_sigv4: true
#aws_region: us-east-1
# Since we are grok matching for apache logs, it makes sense to send them to an OpenSearch index named apache_logs.
# You should change this to correspond with how your OpenSearch indexes are set up.
index: apache_logs
This pipeline configuration is an example of Apache log ingestion. Don’t forget that you can easily configure the Grok Processor for your own custom logs. You will need to modify the configuration for your OpenSearch cluster.
The following are the main changes you need to make:
hosts– Set to your hosts.index– Change this to the OpenSearch index to which you want to send logs.username– Provide your OpenSearch username.password– Provide your OpenSearch password.aws_sigv4– If you use Amazon OpenSearch Service with AWS signing, set this to true. It will sign requests with the default AWS credentials provider.aws_region– If you use Amazon OpenSearch Service with AWS signing, set this value to the AWS Region in which your cluster is hosted.
Fluent Bit
You will need to run Fluent Bit in your service environment. See Getting Started with Fluent Bit for installation instructions. Ensure that you can configure the Fluent Bit http output plugin to your Data Prepper HTTP source. The following is an example fluent-bit.conf that tails a log file named test.log and forwards it to a locally running Data Prepper HTTP source, which runs by default on port 2021.
Note that you should adjust the file path, output Host, and Port according to how and where you have Fluent Bit and Data Prepper running.
Example: Fluent Bit file without SSL and basic authentication enabled
The following is an example fluent-bit.conf file without SSL and basic authentication enabled on the HTTP source:
[INPUT]
name tail
refresh_interval 5
path test.log
read_from_head true
[OUTPUT]
Name http
Match *
Host localhost
Port 2021
URI /log/ingest
Format json
If your HTTP source has SSL and basic authentication enabled, you will need to add the details of http_User, http_Passwd, tls.crt_file, and tls.key_file to the fluent-bit.conf file, as shown in the following example.
Example: Fluent Bit file with SSL and basic authentication enabled
The following is an example fluent-bit.conf file with SSL and basic authentication enabled on the HTTP source:
[INPUT]
name tail
refresh_interval 5
path test.log
read_from_head true
[OUTPUT]
Name http
Match *
Host localhost
http_User myuser
http_Passwd mys3cret
tls On
tls.crt_file /full/path/to/certfile.crt
tls.key_file /full/path/to/keyfile.key
Port 2021
URI /log/ingest
Format json
Next steps
See the Data Prepper Log Ingestion Demo Guide for a specific example of Apache log ingestion from FluentBit -> Data Prepper -> OpenSearch running through Docker.
In the future, Data Prepper will offer additional sources and processors that will make more complex log analytics pipelines available. Check out the Data Prepper Project Roadmap to see what is coming.
If there is a specific source, processor, or sink that you would like to include in your log analytics workflow and is not currently on the roadmap, please bring it to our attention by creating a GitHub issue. Additionally, if you are interested in contributing to Data Prepper, see our Contributing Guidelines as well as our developer guide and plugin development guide.